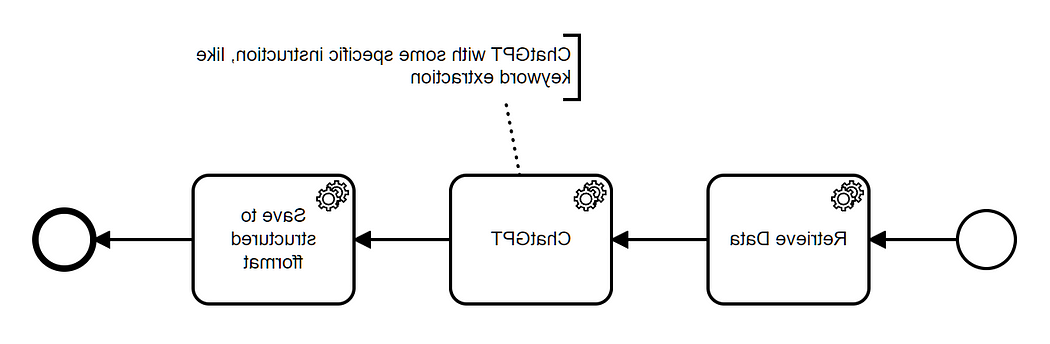
我们将解释如何使用 LangChain 和 ChatGPT. We will create a simple Python script that executes a series of steps:
- Loop through records retrieved by a simple REST API
- Feed the text of each record into ChatGPT for it to extract the relevant keywords
- Parse the ChatGPT response 和 extract the keywords from it
- 统计关键词
- Sort the keywords by their count 和 write them into an Excel sheet
的必备条件
我们将使用Python 3.10与 LangChain 和 ChatGPT. 为此我们创建了一个 水蟒 环境使用这个命令:
Conda create——name langchain python=3.10我们安装了 LangChain 和 ChatGPT 使用下面的命令:
Conda install -c Conda -forge openai
Conda安装-c Conda -forge langchainYou will also need to generate an API key the OpenAI website: http://platform.openai.com/account/api-keys
从REST API中提取数据
You can use virtually any REST API of your choosing which delivers unstructured text. We have used a REST API of a website we created. This API delivers a text-based title 和 description.
In order to get the data from the REST API we have used the 请求 图书馆.
我们也决定用a Python发电机 to loop through each record retrieved by the REST API.
相关的脚本方法有:
def extract_data (json_内容):
"""
Extracts the title, descripton, id 和 youtube id from the json object.
:param json_内容: a JSON object with the video metadata
:return: a tuple with the title, descripton, id 和 youtube id
"""
返回(json_内容['基地']['标题'], json_内容(“基地”)(“描述”), json_内容(“id”), json_内容 [' youtube_id '])
def process_all_records(batch_size: int = 100):
"""
Generator function which loops through all videos via a REST interface.
:param batch_size: The size of the batch retrieved via the REST interface call.
"""
开始= 0
而真正的:
响应=请求.(f”http://admin.thelighthouse.世界/视频?_limit = {batch_size}&开始的地方={}”)
Json_内容 = response.json ()
对于json_内容中的jc:
# Pass the 内容 to the caller using the generator with yield
收益率extract_data (jc)
if len(json_内容) < batch_size:
打破
Start += batch_size使用ChatGPT提取关键字
You can give instructions to ChatGPT to extract keywords in natural language. ChatGPT allows multiple messages per input 和 so we can embed a common instruction 和 then some variable input. 这是我们常用的指令:
You extract the main keywords in the text 和 extract these into a comma separated list. 请在关键字前加上“keywords:”
This is the function which implements the interaction with ChatGPT for keyword extraction:
def extract_keywords_from_chat(chat, record_data):
"""
Sends a chat question to ChatGPT 和 returns its output.
:param chat: The object which communicates under the hood with ChatGPT.
:param record_data: The tuple with the title, description, id 和 youtube id
"""
dt_single = f"{record_data[0]} {record_data[1]}"
Resp = chat([
SystemMessage(内容=
"You extract the main keywords in the text 和 extract these into a comma separated list. Please prefix the keywords with 'Keywords:'"),
HumanMessage(内容= dt_single)
])
答案= resp.内容
返回dt_single,回答And indeed ChatGPT answers most of the time in the expected format. 下面是ChatGPT给出的答案:
Keywords: Golden Heart, 打, 50周年, 促销, 宣传视频.
关键词:Yogesh Sharda, 冥想者, 引导冥想, 内心的自由, 和平的国家, 心, 的关系, 和谐, 个人发展培训师.
处理ChatGPT的输出
Since the output is well formatted we wrote a simple function with regular expressions that extracts the keywords.
def extract_keywords(文本):
"""
Extracts the keywords from the ChatGPT generated text.
:param text:来自ChatGPT的答案, 比如“关键词:金心”, 打, 50周年, 促销, 宣传视频.'
"""
文本=文本.低()
表达式= r".关键词:(.+?)$"
如果再保险.搜索(表达、文本):
关键词:re.Sub (expression, r"\1", text, flags=re.S)
if keywords is not None 和 len(keywords) > 0:
返回(再保险.子(r \.$", "", k.对关键字中的k取条带()).带().分割(" "))
返回[]循环通过和输出到Excel
The final part of the script is just about looping through all records 和 capturing the output in Excel files. We capture the keywords in each records 和 then count the most popular keywords using a Python `计数器集合”.
下面是循环函数:
def process_keywords ():
"""
Instantiates the object which interfaces with ChatGPT 和 loops through the records
capturing the keywords for each records 和 also counting the occurrence of each of these keywords.
"""
chat = ChatOpenAI(model_name=model_name, temperature=0)
popul_keywords = Counter()
关键字_data = []
for i, record_data in enumerate(process_all_records()):
试一试:
dt_single, answer = extract_keywords_from_chat(chat, record_data)
Extracted_keywords = extract_keywords(answer)
popular_keywords.更新(extracted_keywords)
Print (i, dt_single, popul_keywords)
keyword_data.追加({“id”:record_data [2], “youtube_id”:record_data [3], “标题”:record_data [0], “描述”:record_data [1],
“关键词”:”、“.十大正规博彩网站评级(extracted_keywords)})
例外情况如下:
print(f"Error occurred: {e}")
write_to_excel(popular_keywords, keyword_data)And the function which captures the record information with corresponding keywords 和 the overall keyword count in Excel files:
def write_to_excel(popular_keywords, keyword_data):
"""
Captures the keywords of each record in one file 和 then the overall keyword count in another one.
:param popul_keywords:关键字计数器
:param keyword_data: Contains the record data 和 the extracted keywords
"""
pd.DataFrame (keyword_data).to_excel(“keyword_info.xlsx”)
keyword_data = [{'keyword': e[0], 'count': e[1]} for e in popular_keywords.most_common ())
pd.DataFrame (keyword_data).sort_values(=(“计数”),提升= False).to_excel(“popular_keywords.xlsx”)完整的剧本作为 Github要点.
结论
ChatGPT allows multiple messages per input 和 you can take advantage of this by using the SystemMessage LangChain中的参数. 如果在此给出说明 SystemMessage is clear you can use ChatGPT to perform specific NLP tasks, 比如关键词提取, 翻译, 情绪分析, 分类, text generation with specific flavours 和 much more.
The output can then be stored in a structured format. You could represent this idea with a diagramme like this one: